Message Passing Interface (MPI) is used for distributed computing. MPI is not a language it is library used to fork multiple processes and communicate between them using efficient protocols. MPI has many distributions such as MPICH, MVAPICH, OpenMPI etc.
The program below explains simple matrix multiplication using point to point communication in MPI.
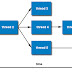
Let's consider matrix1 with 5x4 and another matrix2 with 4x3 dimension after matrix multiplication the resultant matrix become 5x3.Consider we are running this matrix multiplication program for 3 processes then the matrix multiplication is performed as shown in the figure below. We can divide the work by using the for loop as shown below
for(i = rank; i < X; i = i+size)

mpicc matrix_mul.c -o mul
Execute:
mpirun -np 2 ./mul
Output:

Explanation:
Since we are running MPI program on two cores there may be performance gain than sequential code. You can check this difference in sequential and this parallel multiplication by executing mat_mpi_mul.c and mat_seq.c programs for same large dataset(large matrices), for small dataset(matrices with few rows and column) the result for sequential may be efficient due to overhead of creating processes and message transmission.
The table below shows the time taken by sequential and parallel matrix multiplication of 3000x4000 and 4000x2000 with different number of processes on quad core Intel i7 machine with MPICH2 library.

The program below explains simple matrix multiplication using point to point communication in MPI.
Let's consider matrix1 with 5x4 and another matrix2 with 4x3 dimension after matrix multiplication the resultant matrix become 5x3.Consider we are running this matrix multiplication program for 3 processes then the matrix multiplication is performed as shown in the figure below. We can divide the work by using the for loop as shown below
for(i = rank; i < X; i = i+size)
#include"stdio.h"
#include"stdlib.h"
#include"mpi.h"
#define N 4000
#define X 300
#define Y 200
int main(int argc , char **argv)
{
int size,rank,sum=0,i,j,k;
int **matrix1; //declared matrix1[X][N]
int **matrix2; //declare matrix2[N][Y]
int **mat_res; //resultant matrix become mat_res[X][Y]
double t1,t2,result;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
/*----------------------------------------------------*/
//create array of pointers(Rows)
matrix1 =(int **)malloc(X * sizeof(int*));
matrix2 =(int **)malloc(N * sizeof(int*));
mat_res=(int **)malloc(X * sizeof(int*));
/*----------------------------------------------------*/
/*--------------------------------------------------------------------------------*/
//allocate memory for each Row pointer
for(i = 0; i < X; i++)
{
matrix1[i]=(int *)malloc(N * sizeof(int));
mat_res[i]=(int *)malloc(Y * sizeof(int));
}
for(i = 0; i < N; i++)
matrix2[i]=(int *)malloc(Y*sizeof(int));
/*--------------------------------------------------------------------------------*/
for(i = 0; i < X; i++)
{
for(j = 0; j < N; j++)
{
matrix1[i][j] = 1; //initialize 1 to matrix1 for all processes
}
}
for(i = 0; i < N; i++)
{
for(j = 0; j < Y; j++)
{
matrix2[i][j] = 2;//initialize 2 to matrix2 for all processes
}
}
MPI_Barrier(MPI_COMM_WORLD);
if(rank == 0)
t1=MPI_Wtime();
for(i = rank; i < X; i = i+size) //divide the task in multiple processes
{
for(j = 0; j < Y; j++)
{
sum=0;
for(k = 0; k < N; k++)
{
sum = sum + matrix1[i][k] * matrix2[k][j];
}
mat_res[i][j] = sum;
}
}
if(rank != 0)
{
for(i = rank; i < X; i = i+size)
MPI_Send(&mat_res[i][0], Y, MPI_INT, 0, 10+i, MPI_COMM_WORLD);//send calculated rows to process with rank 0
}
if(rank == 0)
{
for(j = 1; j < size; j++)
{
for(i = j; i < X; i = i+size)
{
MPI_Recv(&mat_res[i][0], Y, MPI_INT, j, 10+i, MPI_COMM_WORLD, &status);//receive calculated rows from respective process
}
}
}
MPI_Barrier(MPI_COMM_WORLD);
if(rank == 0)
t2 = MPI_Wtime();
result = t2 - t1;
if(rank == 0)
{
for(i = 0; i < X; i++)
{
for(j = 0; j < Y; j++)
{
printf("%d\t",mat_res[i][j]); //print the result
}
printf("\n");
}
}
if(rank == 0)
printf("Time taken = %f seconds\n",result); //time taken
MPI_Finalize();
return 0;
}
Compile:mpicc matrix_mul.c -o mul
Execute:
mpirun -np 2 ./mul
Output:
Explanation:
Since we are running MPI program on two cores there may be performance gain than sequential code. You can check this difference in sequential and this parallel multiplication by executing mat_mpi_mul.c and mat_seq.c programs for same large dataset(large matrices), for small dataset(matrices with few rows and column) the result for sequential may be efficient due to overhead of creating processes and message transmission.
The table below shows the time taken by sequential and parallel matrix multiplication of 3000x4000 and 4000x2000 with different number of processes on quad core Intel i7 machine with MPICH2 library.


Hi!
ReplyDeleteMy university has a cluster and i'm working on it. Your code is well commented and easy to understand, but don't run very well in the cluster. The matrix resultant calculate in cluster is wrong, because most of the elements is zero. Would you help me?